Reduce Compute Requirements#
This tutorial shows which adjustments one can make to speed up pairOT computations while keeping the method output mostly the same.
This tutorial is based on the original pairOT tutorial.
# Allow JAX to use all available GPU memory
%env XLA_PYTHON_CLIENT_MEM_FRACTION=.99
env: XLA_PYTHON_CLIENT_MEM_FRACTION=.99
from pathlib import Path
import anndata as ad
import pandas as pd
import pairot as pr
0. Required software and data#
Docker containers:
docker pull felix0097/pairot:latest
Datasets:
Required Hardware:
We used a Nvidia A40 GPU for this tutorial (48GB VRAM). Less VRAM is fine as well, you need to reduce the
batch_sizeparameter accordingly then.Moreover, for the
Data preparationsection, we recommend around 128GB of system memory
1. Data preparation#
query_dataset = "7d7cabfd-1d1f-40af-96b7-26a0825a306d"
ref_dataset = "ced320a1-29f3-47c1-a735-513c7084d508_CAP"
# Update paths below
raw_data_path = Path("raw/")
preproc_data_path = Path("preprocessed/")
# Preprocess datasets, this includes:
# 1. Aligning/sort gene space
# 2. Do differential expression testing
# 3. Select highly variable genes
adata_query, adata_ref = pr.pp.preprocess_adatas(
ad.read_h5ad(raw_data_path / f"{query_dataset}.h5ad"),
ad.read_h5ad(raw_data_path / f"{ref_dataset}.h5ad"),
n_top_genes=350, # use less number of highly variable genes to speed up Spearman correlation computation
cell_type_column_adata1="cell_type_author",
cell_type_column_adata2="cell_type_author",
sample_column_adata1="sample_id",
sample_column_adata2="sample_id",
n_samples_auroc=10_000, # only use 10,000 samples per cluster to speed up AUROC computation
n_samples_hvg_selection=100_000, # only use 100,000 cells for HVG selection to reduce memory foot print
)
# Cache preprocessed data
adata_query.write_h5ad(preproc_data_path / f"{query_dataset}_small.h5ad")
adata_ref.write_h5ad(preproc_data_path / f"{ref_dataset}_small.h5ad")
adata1: (600929, 37976)
adata2: (1265624, 38114)
Sub-setting gene space to genes that are expressed in both datasets...
adata1: (600929, 18130)
adata2: (1265624, 18130)
Calculating differentially-expressed genes...
Sub-setting to highly variable genes...
adata1: (600929, 350)
adata2: (1265624, 350)
Changes to default settings:
n_top_genes: Use 350 instead of 750 HVGs for computation of Spearman correlation. This reduces the GPU memory consumption and also speeds up the computation of the optimal transport modeln_samples_auroc: Sub-sample to max 10.000 samples to calculate AUROC scores for each gene. This will drastically, speed up the computation of AUROC scores.n_samples_hvg_selection: Only use 100.000 genes per dataset to calculate highly variable genes. This will reduce memory consumption.
2. Initialize pairOT model#
adata_query = ad.read_h5ad(preproc_data_path / f"{query_dataset}_small.h5ad")
adata_ref = ad.read_h5ad(preproc_data_path / f"{ref_dataset}_small.h5ad")
# Subsample data before fitting OT model to speed up computation
# To NOT loose rare cell-types, we only sub-sample cell-type clusters with more than n_samples samples
adata_query = adata_query[
pr.pp.downsample_indices(
adata_query.obs.cell_type_author.to_numpy(),
n_samples=10_000,
),
:,
]
adata_ref = adata_ref[
pr.pp.downsample_indices(
adata_ref.obs.cell_type_author.to_numpy(),
n_samples=10_000,
),
:,
]
print(f"adata1: {adata_query.shape}")
print(f"adata2: {adata_ref.shape}")
adata1: (169407, 350)
adata2: (272139, 350)
Changes to default settings:
We subsample the data before fitting the optimal transport model.
The optimal transport model scales quadratically in the number of samples:
n_samples_query * n_samples_ref
dataset_map = pr.tl.DatasetMap(adata_query, adata_ref)
dataset_map.init_geom(
batch_size=12288,
epsilon=0.05,
)
Changes to default settings:
batch_sizeWe can now increase batch size (if the original data already fitted into memory)
If the original data did not fit into memory, we now have a way higher chance that we’re able to fit the model now
print(f"x size: {dataset_map.geom.x.shape[0] * dataset_map.geom.x.shape[1] * 4 / 1000**3} GB")
print(f"y size: {dataset_map.geom.y.shape[0] * dataset_map.geom.y.shape[1] * 4 / 1000**3} GB")
x size: 0.237847428 GB
y size: 0.382083156 GB
3. Fit pairOT model#
dataset_map.init_problem(tau_a=1.0, tau_b=1.0)
dataset_map.solve()
Fitting the pairOT model is significantly faster now. We could reduce the time it takes to fit the model from ~4 hours to less than 15min.
To summarize how we achived this speedup:
Only using 350 highly variable genes instead of 750. Hence, speeding up the computation of the Spearman correlation. As has been shown by Crow et al., this only has very minor effects on the calculated distances. But, significantly reduces computational costs. Moreover, this also reduces the GPU memory consumption.
Using less cells when fitting the optimal transport model. Again, this leaves the output mostly the same, while considerably reducing computational costs given that the OT model scales quadratically in the number of samples.
4. Results of pairOT#
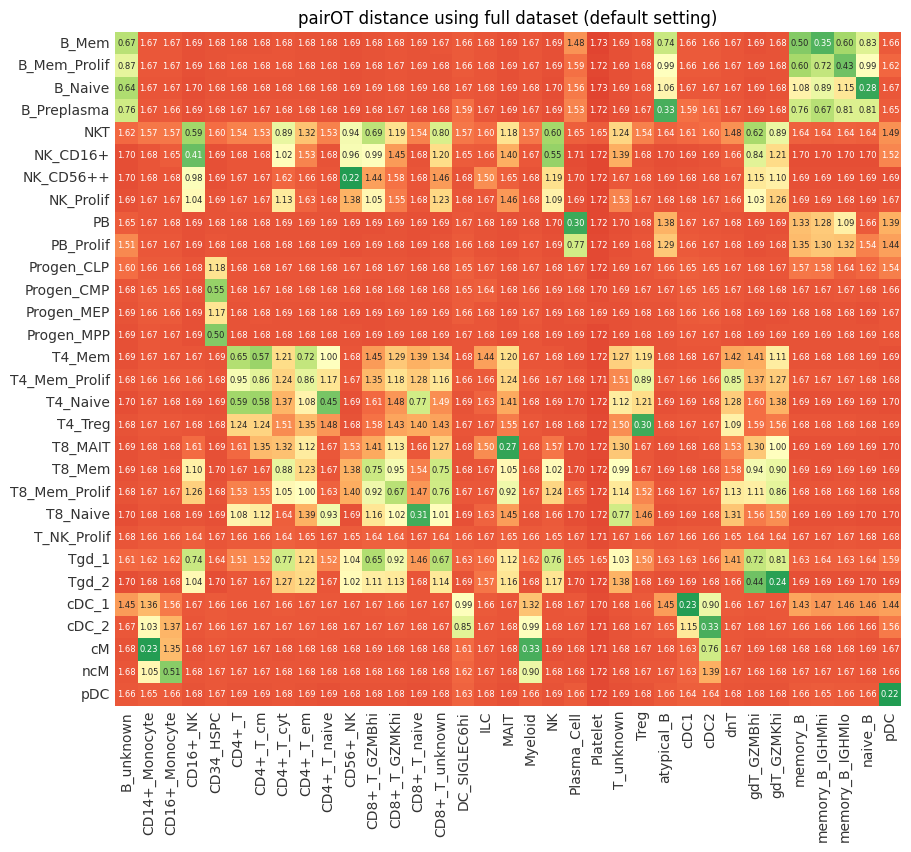
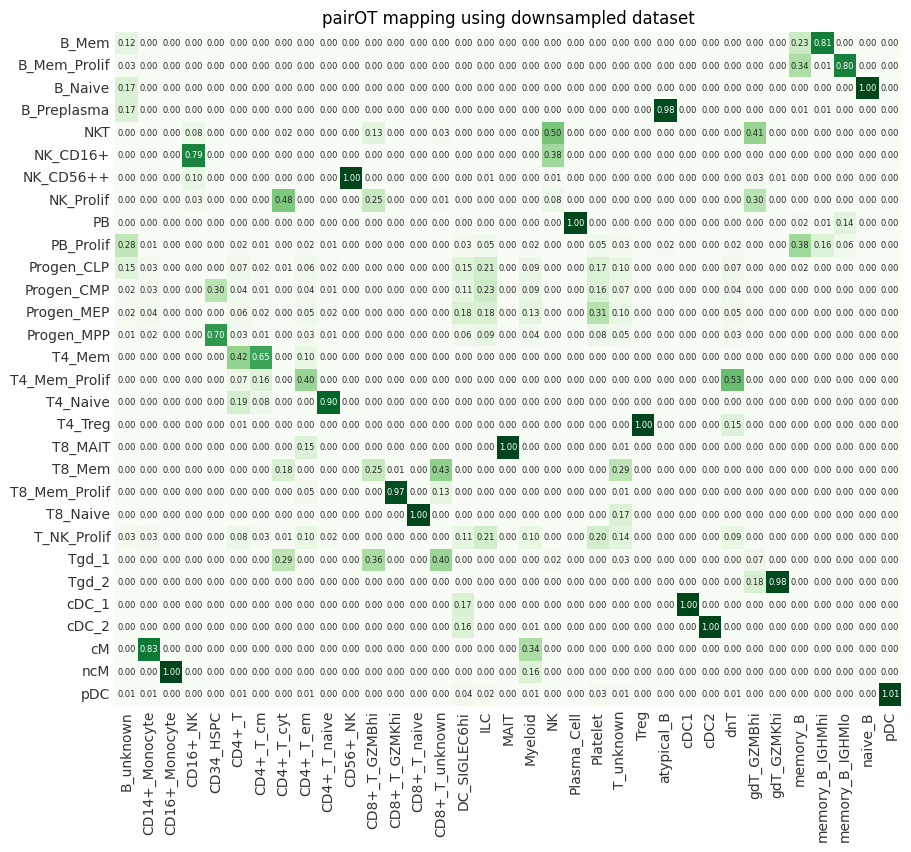
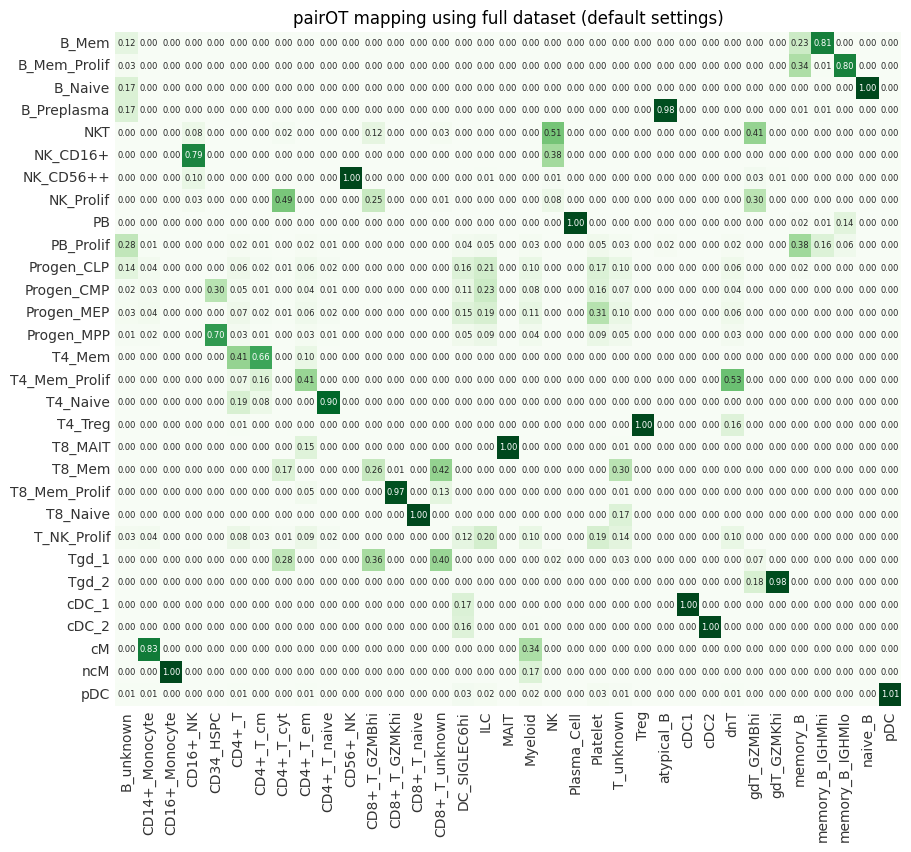
We can now compare the results of the downsampled pairOT model to the one that was fitted on the full dataset (see Tutorial.ipynb). As we can see below, the downsampling has little effect on the outputs of pairOT (mapping + distances), while signficantly reducing computational costs.
OT mappings#
mapping = dataset_map.compute_mapping()
ax = pr.pl.mapping(mapping, sort_by_score=False, backend="matplotlib")
ax.set_title("pairOT mapping using downsampled dataset");
mapping_full = pd.read_parquet("mapping_mean.parquet")
ax = pr.pl.mapping(mapping_full, sort_by_score=False, backend="matplotlib")
ax.set_title("pairOT mapping using full dataset (default settings)");
Cluster distance#
distance = dataset_map.compute_distance()
ax = pr.pl.distance(distance, backend="matplotlib")
ax.set_title("pairOT distance using downsampled dataset");
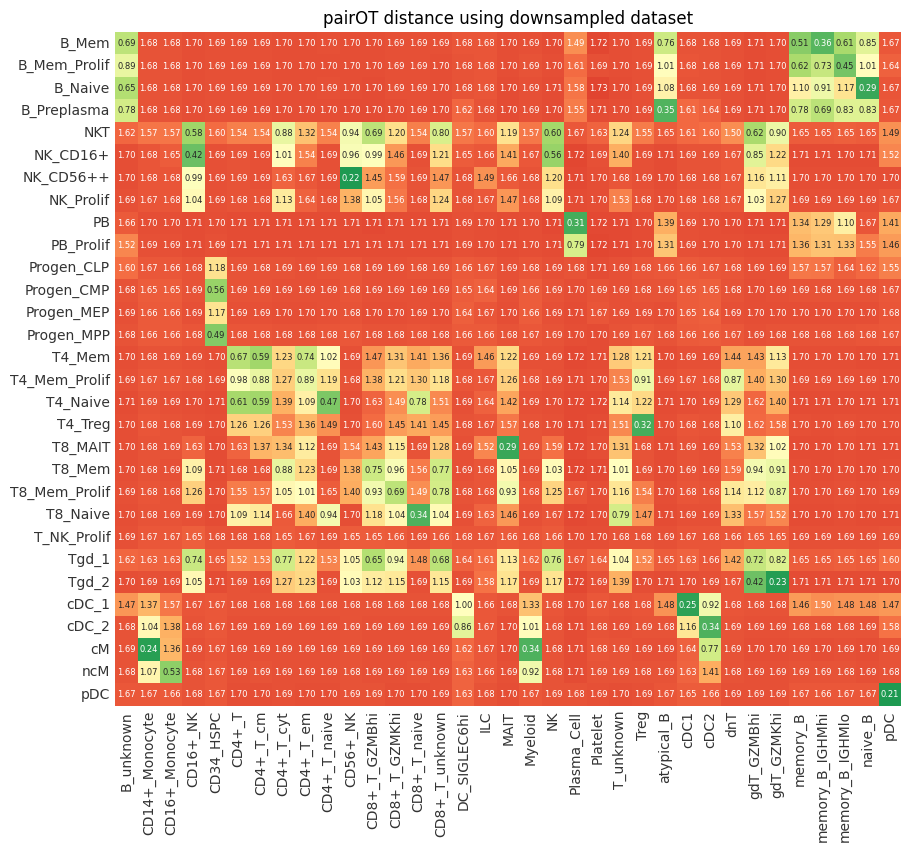
distance_full = pd.read_parquet("distance.parquet").sort_index().sort_index(axis=1)
ax = pr.pl.distance(distance_full, backend="matplotlib")
ax.set_title("pairOT distance using full dataset (default setting)");